
在昨晚的 OpenAI 旧金山开发者大会( DevDay) 上 。OpenAI 公布了五项重大创新,其中“实时 API”(Realtime API)的新功能,使得开发者能够创建具有低延迟、AI 生成的语音响应功能的应用程序。尽管这一功能不完全等同于 ChatGPT 的高级语音模式,但其能力已经非常接近,旨在帮助开发者为用户提供近乎实时的语音到语音互动体验。除此之外,OpenAI 还发布了其他一系列新功能,旨在进一步提升开发者的 AI 应用构建体验。
包括实时语音API、提示词缓存、模型蒸馏、视觉微调、新Playground。
这些创新将改变开发者与AI互动的方式,并有助于降低AI模型的使用成本,推动多模式的语音、视觉等应用的普及。
顺道说一下,今年开发者大会一共 3 场:10月1号旧金山;10月30号伦敦,以及11月21日新加坡…

实时语音API
OpenAI发布——实时API(Realtime API),该API允许开发者在应用中构建低延迟的多模态语音体验。
- 实时API的推出:
- 实时API允许开发者构建低延迟的语音转语音体验,支持自然的情感对话交互,有六种预设语音。
- 该API的公共测试版现已向所有付费开发者开放。
- 音频输入与输出:
- 在聊天完成API中引入音频输入和输出,适用于不需要低延迟的应用场景。
- 开发者可以将文本或音频输入传递给GPT-4o,模型可以以文本、音频或两者形式返回响应。这使得应用场景更加灵活。

- 工作原理:
- 简化流程:传统上,开发者需要使用多个模型(如自动语音识别、文本推理、文本转语音)来创建语音助手体验,这样会导致延迟和情感表达的损失。
- 单一API调用:通过实时API,开发者可以通过一次API调用处理整个过程,尽管仍然比人类对话慢。
- WebSocket连接:实时API创建持久的WebSocket连接,允许开发者与GPT-4o实时交换消息。
- 函数调用支持:支持函数调用,使得语音助手能够执行用户请求,例如下订单或检索客户信息。
- 应用场景:
- 实时API可用于客户支持、语言学习、教育软件等,开发者可以利用语音交互增强用户体验。
- 例如:开发者通过该 API 仅用30秒便构建了一个旅行计划应用,让用户可以通过自然语言交互实现行程规划。
Speak 是一款语言学习应用程序,它使用 Realtime API 来支持其角色扮演功能,鼓励用户用新语言练习对话。
Healthify 是一款营养和健身指导应用程序,它使用实时 API 实现与其 AI 教练 Ria 的自然对话,同时在需要个性化支持时让人类营养师参与进来。
- 定价与可用性:
- 文本输入令牌:每百万5美元,输出令牌:每百万20美元。
- 音频输入:每百万100美元,输出:每百万200美元。
- 这相当于每分钟音频输入约0.06美元,音频输出约0.24美元。
- 安全性与隐私:
- 安全保护措施:实时API采用多层安全保护,包含自动监控和人工审核,以减少API滥用风险。
- 隐私承诺:OpenAI承诺不在未经用户明确允许的情况下使用服务中的输入或输出进行模型训练。
- 未来计划:
- 更多交互方式:计划逐步增加视觉和视频等其他交互方式。
- 提高速率限制:当前速率限制为Tier 5开发者约100个同时会话,未来将增加以支持更大规模的部署。
- 官方SDK支持:将实时API集成到OpenAI的Python和Node.js SDK中,方便开发者使用。
- 提示缓存支持:允许开发者以折扣价重新处理之前的对话内容。
- 扩展模型支持:未来版本将支持GPT-4o mini。
演示实例
- 演示示例: OpenAI 展示了一个旅行规划应用的原型,用户可以通过与 AI 助手对话来讨论即将到来的伦敦之旅,AI 会提供低延迟的语音回复,并在地图上标注推荐的餐馆。

- 集成 API: OpenAI 演示了将其与 Twilio 的 API 相结合的能力,AI助手通过电话向一家虚构的糖果店下单购买400个巧克力草莓。尽管 OpenAI 的实时 API 无法直接打电话给商家,但它可以与 Twilio 等电话 API 集成,模拟 AI 助手打电话下单。这种结合使得 AI 具备处理电话沟通任务的能力,不过 OpenAI 并没有为这种交互增加 AI 声音的自动识别提示,是否告知对方是 AI 仍由开发者决定。需要注意的是,根据加州最新的法律,或许开发者在某些情况下必须提供这种识别提示。
提示词缓存
OpenAI 还推出了 Prompt 缓存功能允许开发者在多个 API 请求之间缓存常用的上下文信息,从而减少重复计算和成本。OpenAI 表示,这一功能能够为开发者节省高达 50% 的费用。
这一功能与竞争对手 Anthropic 的类似功能相似,后者声称其缓存功能能为开发者节省 90% 的成本。随着 AI 市场竞争加剧,OpenAI 也在通过降价等措施吸引开发者。据报道,OpenAI 在过去两年内已经将其 API 的访问成本降低了 99%。

- 功能概述:
- 提示缓存的目的:许多开发者在使用 API 时,会在多个调用中重复使用相同的上下文,例如在代码编辑或与聊天机器人进行长时间的多轮对话。提示缓存允许开发者通过重用最近见过的输入标记来减少不必要的开销。
- 折扣与效率:通过使用提示缓存,开发者可以获得高达 50% 的折扣,并且处理速度也会更快。这意味着在多次调用中,开发者可以显著降低 API 的使用成本。
- 可用性与定价:
- 适用模型:提示缓存功能从 2024 年 10 月 1 日起自动应用于最新版本的 GPT-4o、GPT-4o mini、o1-preview 和 o1-mini 以及这些模型的微调版本。
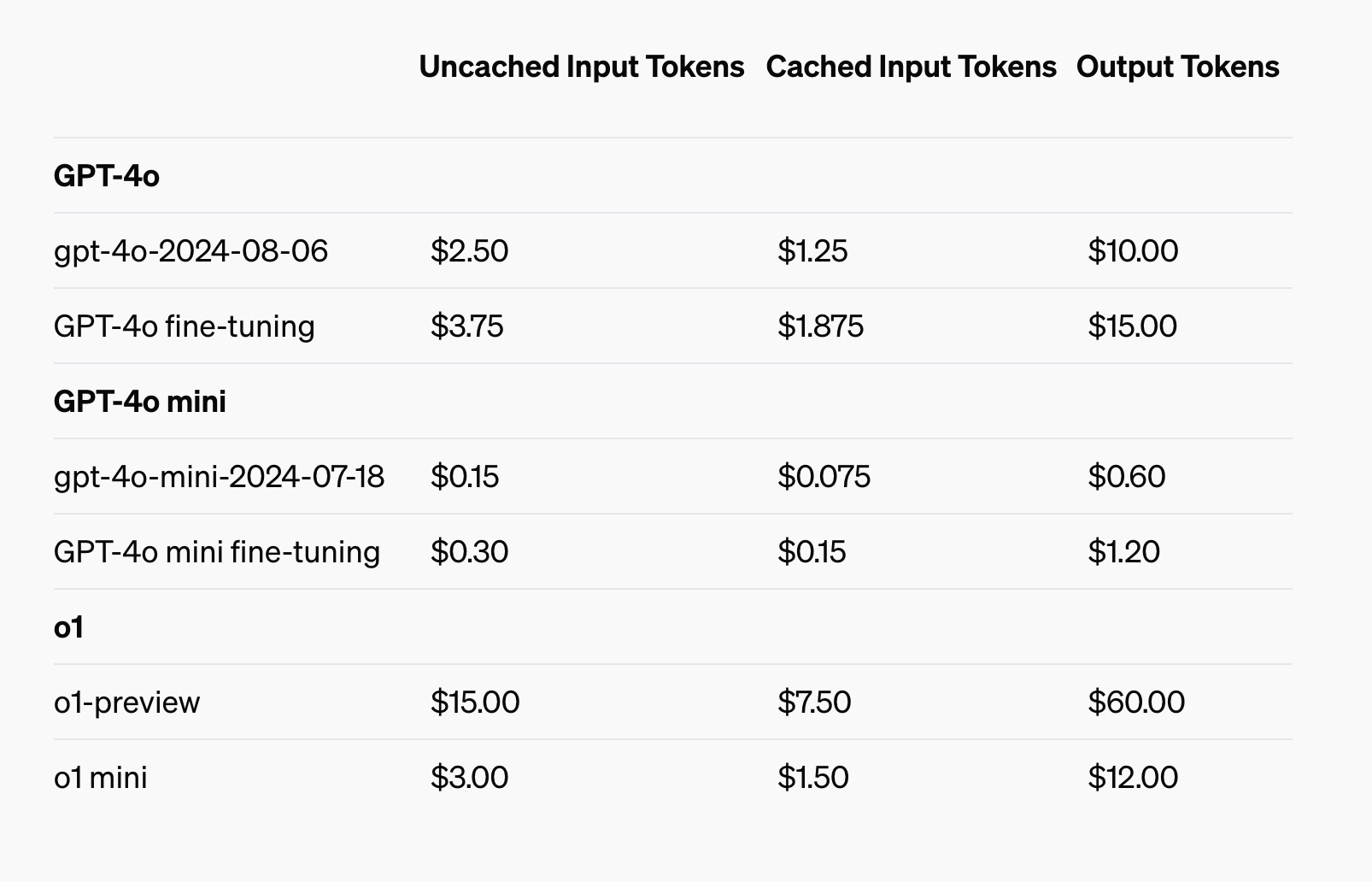
- 定价结构:
- GPT-4o:
- 未缓存输入:$2.50
- 缓存输入:$1.25
- 输出标记:$10.00
- GPT-4o mini:
- 未缓存输入:$0.15
- 缓存输入:$0.075
- 输出标记:$0.60
- o1:
- 未缓存输入:$15.00
- 缓存输入:$7.50
- 输出标记:$60.00
- GPT-4o:
- 这种定价策略使得开发者能够根据具体需求选择更具成本效益的选项。
- 缓存使用监控:
- 缓存条件:API 调用需超过 1,024 个标记才能自动享受提示缓存的优惠。系统会缓存之前计算过的提示的最长前缀,并从 1,024 个标记开始,以 128 个标记的增量增加。
- 自动应用:如果开发者重用具有相同前缀的提示,系统会自动应用提示缓存折扣,无需开发者进行任何额外的 API 集成更改。
- 缓存清除机制:缓存通常在 5 到 10 分钟的不活动后被清除,并且在最后使用后的一个小时内总会被移除。这一机制确保了数据的安全性和隐私。
提示缓存功能为开发者在生产环境中扩展应用程序提供了一种有效的工具,能够在性能、成本和延迟之间取得平衡。它不仅降低了使用成本,还提高了响应速度,促进了 AI 应用的开发与扩展。
模型蒸馏
模型蒸馏是通过使用更强大模型的输出对较小且成本效益高的模型进行微调,使其在特定任务上以更低成本达到高级模型的性能。
也就是允许开发者使用大模型(例如o1-preview或GPT-4o)来微调较小的模型(例如GPT-4o mini)。这种方法使得小公司或资源有限的开发团队能够使用与大模型接近的能力,而无需承担高昂的计算成本。

应用场景:小公司或初创企业可以利用这一技术,在较小的设备或计算资源上运行具备大模型性能的AI模型。这对于在计算资源有限的场景下使用AI模型具有重大意义,例如农村诊所使用AI诊断工具的场景。
优势:通过模型蒸馏,开发者可以在性能和计算资源之间取得平衡,在保证模型有效性的前提下减少计算资源的消耗,从而扩大AI技术的应用范围。
使用流程
a. 创建评估
- 开发者首先需要创建一个评估,测量希望提炼的模型(例如GPT-4o mini)的性能。这个评估将用于持续监测蒸馏模型的表现,以帮助决定是否进行部署。
b. 创建蒸馏数据集
- 使用存储完成功能,开发者可以利用GPT-4o的输出生成一个真实世界示例的数据集。通过在Chat Completions API中设置“store:true”标志,可以自动存储输入输出对,而不会影响延迟。
- 存储的完成可以经过审查、过滤和标记,以确保生成高质量的数据集用于微调和评估。
c. 微调模型
- 利用创建的蒸馏数据集对GPT-4o mini进行微调。存储完成可以作为训练文件使用。
- 微调是一个迭代过程,开发者可以根据初步结果调整数据集、训练参数,或捕获更多特定的示例,以不断改进模型性能。
可用性与定价
- 可用性:模型蒸馏服务现已向所有开发者开放,支持蒸馏任何模型,包括GPT-4o和o1-preview。
- 免费使用:为了帮助开发者入门,OpenAI提供每天2M的免费训练代币用于GPT-4o mini,以及1M的免费训练代币用于GPT-4o,直到2024年10月31日。
- 后续定价:超出免费额度后,蒸馏模型的训练和运行费用与标准微调价格一致,具体费用可以在OpenAI的API定价页面查看。
视觉微调
功能介绍:OpenAI推出了GPT-4o的视觉微调功能,使开发者能够通过图像和文本微调模型的视觉理解能力,从而提升其视觉理解能力。通过视觉微调,开发者能够利用少量的视觉训练数据来实现显著的性能提升,为AI视觉应用提供了更多的可能性,如自动驾驶、视频监控、医学成像、视觉搜索等领域。

这一功能旨在改善 AI 对视觉内容的理解和处理能力,对于需要视觉和文本交互的任务,这一功能尤其重要。然而,OpenAI 对上传的图像有严格的限制,禁止上传含有版权、暴力或其他违反 OpenAI 安全政策的图片,例如著名的迪士尼角色图片等。
- 微调过程:
- 视觉微调的过程与文本微调类似,开发者需要准备符合格式的图像数据集,并将其上传至平台。仅需100张图像即可提升模型在视觉任务上的表现。
- 实际应用示例:
- Grab:通过视觉微调,Grab提升了交通标志定位和车道分隔线计数的准确性,其中车道计数的准确性提高了20%,限速标志的定位准确率提高了13%。
Grab 是一家领先的食品配送和共享出行公司,利用司机收集的街景图像将其转化为支持 GrabMaps 的地图数据。GrabMaps 是一个为其在东南亚的所有业务提供服务的地图平台。通过仅使用 100 个示例进行视觉微调,Grab 成功地教会了 GPT-4o 准确定位交通标志并计算车道分隔线,从而优化了地图数据。因此,Grab 将车道计数的准确性提高了 20%,限速标志的定位准确性提高了 13%,使得他们能够更好地实现地图操作的自动化,取代了之前的手动流程。

- Automat:利用视觉微调,Automat将桌面机器人在业务自动化中的成功率从16.60%提升至61.67%。
Automat 是一家企业自动化公司,专注于构建桌面和网络代理,处理文档并执行基于用户界面的操作,以实现业务流程的自动化。通过视觉微调和一组屏幕截图,Automat 训练了 GPT-4o,使其能够根据自然语言描述定位屏幕上的用户界面元素,从而将 RPA 代理的成功率从 16.60%提升至 61.67%,相较于基础版 GPT-4o,性能提升达 272%。此外,Automat 还仅用 200 张非结构化保险文件的图像训练 GPT-4o,使其在信息提取任务中的 F1 分数提升了 7%。
- Coframe:通过对GPT-4o进行图像和代码的微调,Coframe提高了网站生成的一致性和布局正确性,提升幅度为26%。
Coframe 正在开发一个 AI 增长工程助手,旨在帮助企业持续创建和测试其网站及用户界面的不同版本,以优化业务指标。这个任务的关键在于根据网站的其他部分自主生成新的品牌网站部分。Coframe 委托 GPT-4o 根据图像和现有代码生成网站的下一部分代码。通过对 GPT-4o 进行图像和代码的微调,他们将模型生成具有一致视觉风格和正确布局的网站的能力提高了 26%。
 现有的网站,模型的目标是与其相匹配。
现有的网站,模型的目标是与其相匹配。 使用 GPT-4o 基础模型生成的输出。
使用 GPT-4o 基础模型生成的输出。 输出采用GPT-40对视觉和文字进行微调,更贴合页面风格
输出采用GPT-40对视觉和文字进行微调,更贴合页面风格
- Grab:通过视觉微调,Grab提升了交通标志定位和车道分隔线计数的准确性,其中车道计数的准确性提高了20%,限速标志的定位准确率提高了13%。
新的 Playground

在Playground中,你可以通过简单地描述你想使用模型实现的功能,Playground会自动为你生成提示(prompts)和有效的schema(模式)。这些提示和schema可以用于调用函数以及生成结构化的输出。
- 生成提示:你只需要告诉Playground你想让模型做什么,它就会自动生成一个合适的提示语句。这可以大大简化你手动编写提示的过程,帮助你快速启动项目。
- 有效的schema:如果你需要模型输出某种特定格式的结果,比如JSON、列表、表格等,Playground会自动为你生成符合这种格式要求的结构化输出模式。这样可以确保模型的输出符合你的预期结构。
主要作用:
这个功能的目的是帮助开发者更快地构建原型,不再需要手动编写复杂的提示或输出格式。只需描述你想完成的任务,Playground就能自动生成所需的代码和提示,从而让你快速测试和实现想法。
适用场景:
例如,你想开发一个客服机器人,你可以在Playground中输入:“我想创建一个客服机器人,它能够回答客户的常见问题。” Playground会根据这个描述自动生成适合的提示,并为机器人的功能生成合适的代码结构,帮助你快速实现和测试这个想法。
这个功能的目的是减少开发者的工作量,加速AI项目的开发过程。







